IMDEA Networks


Home
![]() The Data Transparency Group (DTG) is employing a mix of network measurements, distributed systems building, algorithms, and machine learning to study problems and propose solutions to transparency issues related to data privacy, the economics of data, information and disinformation spread, and automated decision making via machine learning algorithms. The objective of the group is to tackle important problems at the forefront of the interplay between technology, society, public policy, and economics. On all of the above we take a holistic approach that goes from fundamental thinking and rethinking, all the way to developing code running on large systems and devices, including all the business challenges for transforming visions and ideas to real world services.
The Data Transparency Group (DTG) is employing a mix of network measurements, distributed systems building, algorithms, and machine learning to study problems and propose solutions to transparency issues related to data privacy, the economics of data, information and disinformation spread, and automated decision making via machine learning algorithms. The objective of the group is to tackle important problems at the forefront of the interplay between technology, society, public policy, and economics. On all of the above we take a holistic approach that goes from fundamental thinking and rethinking, all the way to developing code running on large systems and devices, including all the business challenges for transforming visions and ideas to real world services.

Team
Scientific Direction

Investigación





Alumni Network

Former Members
- Marius Paraschiv (Post-Doc Researcher, 2019-2023). Currently a senior researcher leading Quantum Information Group at IMDEA Networks.
- Álvaro Garcia-Recuero (Post-Doc Researcher, 2020-2022).

Publications
FLEAT: Energy-Accuracy Trade-off in Federated Learning over Heterogeneous Edge Devices
Javad Dogani, Reza Namvar, Masoumeh Khodarahmi, Farshad Khunjush, Nikolaos Laoutaris
IEEE Transactions on Mobile Computing. 10.1109/TMC.2026.3710334. IEEE. ISSN: 1536-1233. Julio 2026
Index-only Backdoor Vetting for Secure Federated PEFT of Large Language Models
Javad Dogani, Devriş Işler, Nikolaos Laoutaris
International Conference on Machine Learning. Seoul, South Korea. Julio 2026
Quantifying the Robustness of Smart Street Parking Assignment to Sensor Noise
Behafarid Hemmatpour, Javad Dogani, Nikolaos Laoutaris
IEEE International Conference on Mobile Data Management. Athens, Greece. Julio 2026
Privacy-preserving Chunk Scheduling in a BitTorrent Implementation of Federated Learning
Naicheng Li, Javad Dogani, Rui Wang, Kaitai Liang, Nikolaos Laoutaris
International Conference on Distributed Computing Systems. Seoul, South Korea. Junio 2026
SemanticDFL: Similarity-Aware Pull-based Personalized Decentralized Federated Learning
Javad Dogani, Mostafa Khastkhodaei, Farshad Khunjush, Nikolaos Laoutaris
Measurement and Modeling of Computer Systems. Ann Arbor, MI, USA.. Junio 2026
Robustness of Smart Parking Assignment Under Realistic Sensor Noise (Poster)
Behafarid Hemmatpour, Javad Dogani, Nikolaos Laoutaris
ACM/IEEE International Conference on Embedded Artificial Intelligence and Sensing Systems. Saint-Malo, France. Mayo 2026
Reducing Street Parking Search Time via Smart Assignment Strategies
Behafarid Hemmatpour, Javad Dogani, Nikolaos Laoutaris
ACM International Conference on Advances in Geographic Information Systems. Minneapolis, MN, USA. Noviembre 2025
Pallas: A Data-Plane-Only Approach to Accurate Persistent Flow Detection on Programmable Switches in High-Speed Networks
Weihe Li, Beyza Bütün, Tianyue Chu, Marco Fiore, Paul Patras
IEEE International Conference on Network Protocols. Seoul, South Korea. Septiembre 2025
MUDGUARD: Taming Malicious Majorities in Federated Learning using Privacy-Preserving Byzantine-Robust Clustering
Rui Wang, Xingkai Wang, Huanhuan Chen, Jérémie Decouchant, Stjepan Picek, Nikolaos Laoutaris, Kaitai Liang
Measurement and Modeling of Computer Systems. Stony Brook, New York, USA. Junio 2025
- 1
- 2
- 3
- …
- 5
- arrow_forward_ios
Downloads
Data Economy: We are working towards developing a formal theory, and a set of methods and systems, for realising in practice the “data is the new oil” analogy, especially its human Centric version, in which individuals get compensated by online and offline services that collect and use their data [IEEE Internet Computing]. We are looking at fundamental questions and problems such as: (1) How do you split the value of a dataset among all the individuals and sources that contribute to it? [arXiv:2002.11193] [arXiv:1909.01137]; (2) As a data buyer, how do you select which of the available datasets to buy in an open data marketplace?; (3) How do you implement in practice a safe, fair, distributed, and transparent data marketplace?
Sensitive Personal Data and the Web: We are working on several algorithms, methodologies, and tools for shedding more light to what happens to our personal data, especially those that are deemed sensitive, on the web. For example with eyeWndr we developed an algorithm and a browser addon for detecting targeting in online advertising [ACM CoNEXT’19]. For targeting to work, trackers need to collect interests, intentions, and behaviors of users at a massive scale. In [ACM IMC’18] we showed that, unlike popular belief, most tracking flows carrying data of European citizens start and terminate within the EU. European Data Protection Authorities (DPA) could, therefore, investigate more easily matters of compliance with GDPR and other legislations. The latter becomes particularly important in the case that trackers collected sensitive personal data, e.g., related to health, political beliefs, sexual preference etc., that are protected by additional clauses under GDPR. In our most recent work, we developed automated classifiers for detecting web-pages that contain such sensitive data [ACM IMC’20]. Applying our classifiers to a snapshot of the entire English-speaking web we found that some 15% of it includes content of sensitive character.
Detection of Fake News in Social Media and the Web: As part of our ongoing research, we are developing algorithms and knowledge-extraction methods for detecting and analyzing fake news in social media and more general web platforms. As more people become reliant on information spread in their social media circles, they also become more vulnerable to manipulation and misinformation. Whether it is part of an intentional and organized campaign or simply the result of lack of knowledge in a general area, fake news represents one of the most important challenges of a modern digital society. Our approach relies on (1) creating efficient crawling methods that can provide large quantities of data, readily updated and in a scalable manner, (2) using state-of-the-art graph analysis and prediction algorithms, such as graph neural networks to perform detection, of possible fake-news sources, as well as to analyze the spread of such information through the network, (3) gain an understanding of false news occurrence and spread, depending on network type, user activity or factors external to the network itself. An important aspect is that the solutions thus found take into consideration user-needs, as well as the technological and legal constraints involved in this process. They are, furthermore, general, and can be readily applied to other types of information-spread paradigms, such as epidemic detection or cyberthreat detection, among others.
Early Warning Systems for Epidemics Spread: We are developing an early warning system for predicting epidemic spread and risk of contagion using mobile phone data to detect possible hospitalizations, tracking the risk connections with other users and detecting the most likely places of contagion. The solution is based on machine learning techniques and it poses many innovative advantages over the state of the art, which are that: (1) the data is already there for millions of people, (2) the coarse granularity of cell tower sectors is large enough to protect the anonymity of people but small enough to be useful when considering areas that may be more dangerous than others, (3) the solution can be obtained without any data leaving the data controller, (4) the solution can be presented either on web-pages that you have to visit to know in which areas to be more careful and/or in the form of a smartphone app that will warn you with a notification of danger whenever you enter risky areas. Moreover, (5) this solution is user-centered and (6) it can also be generalized so it can be adopted by different cities and focused in future infectious diseases, to predict the early spatial evolution and design spatio-temporal programs for disease control.
Example of risk map movie from London for the period of March and April, 2020:
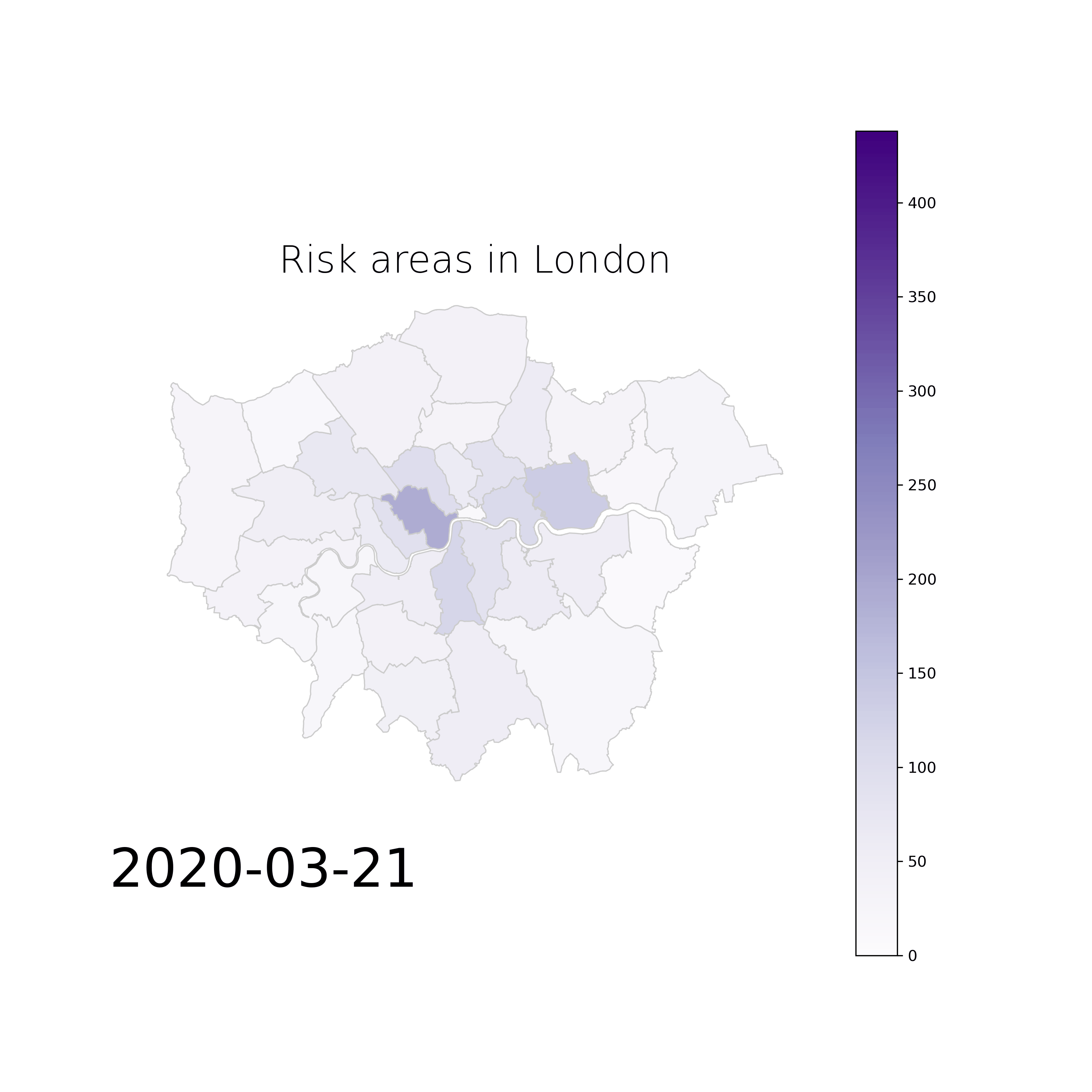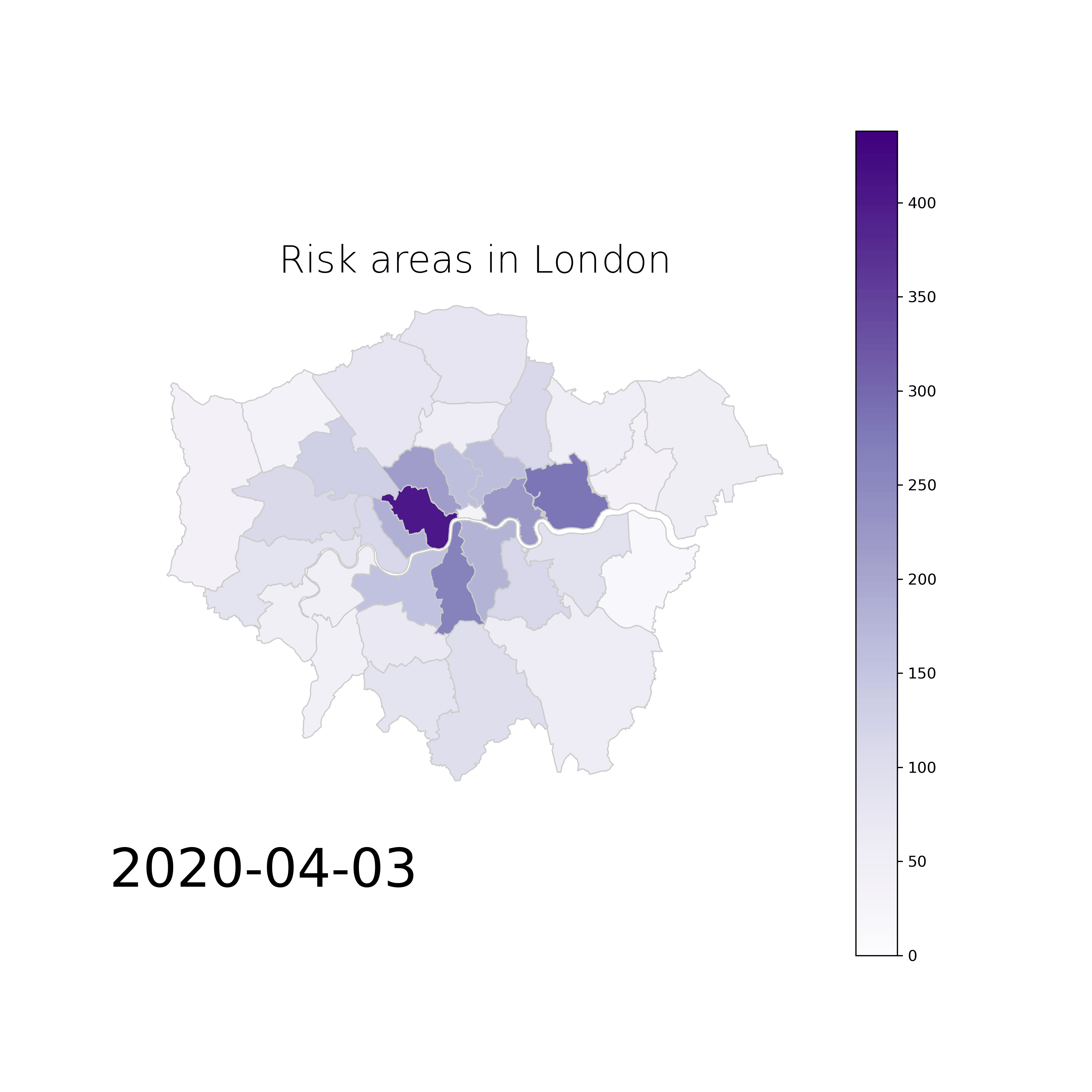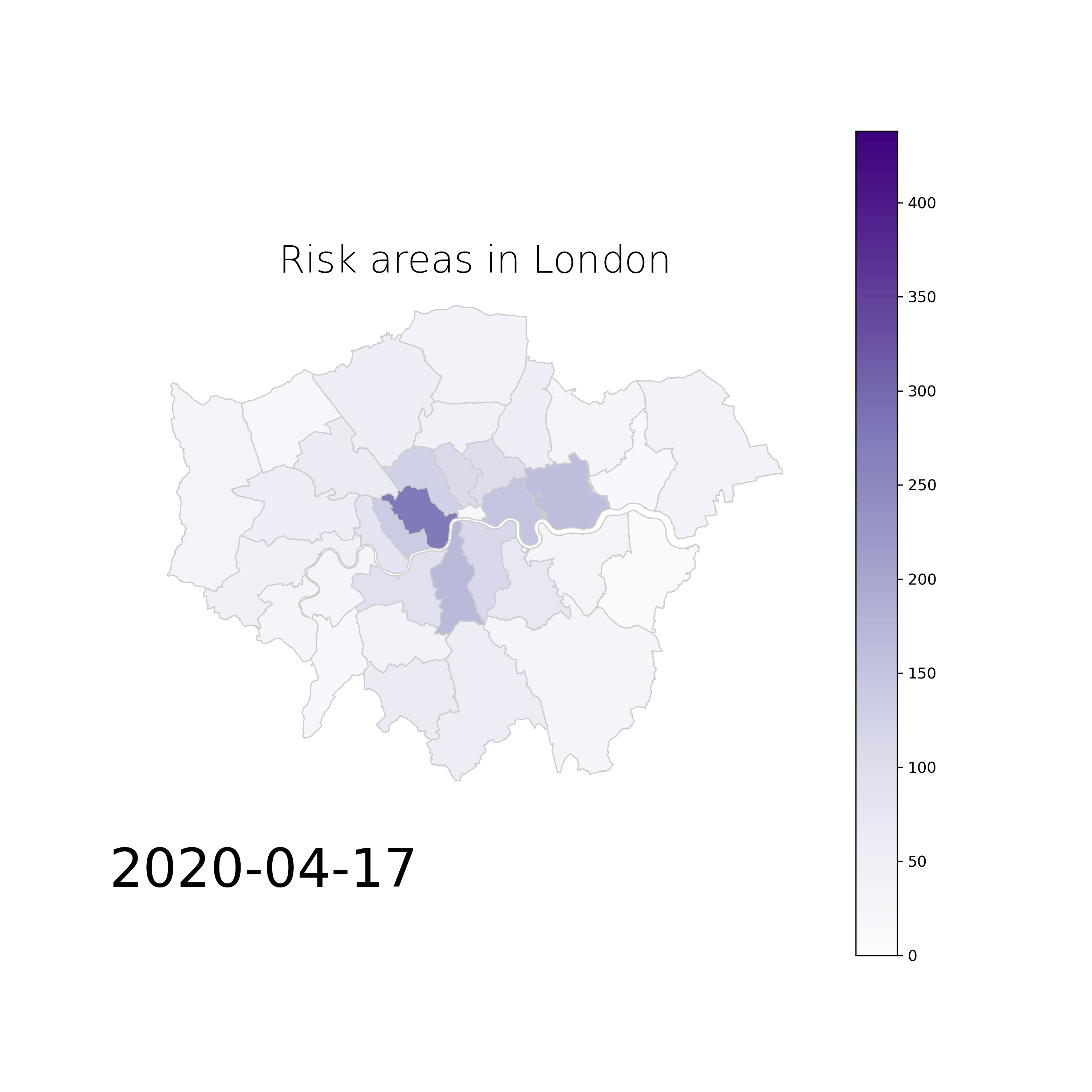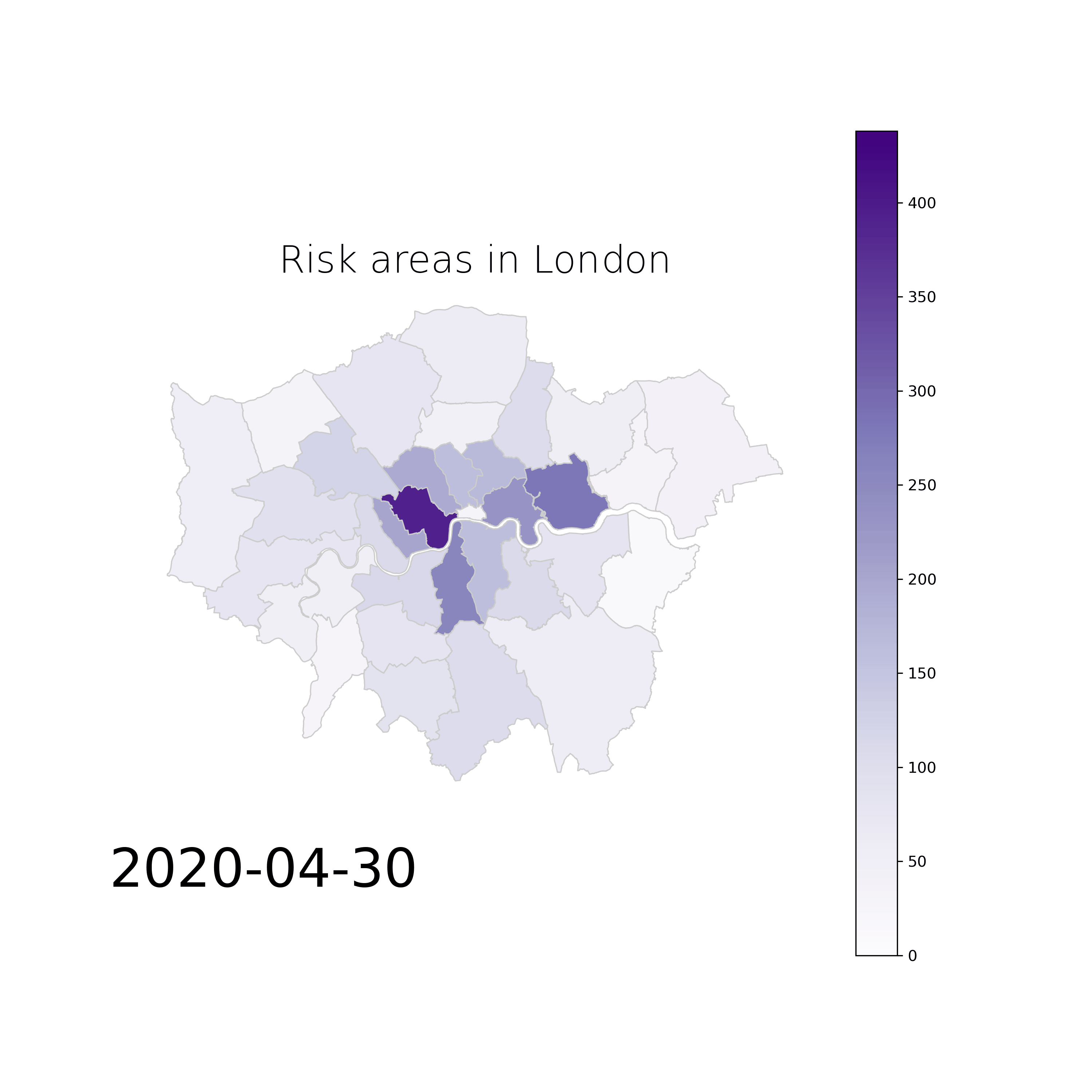
Data Watermarking and Privacy by Design: In our most recent strand of work around privacy and the economics of data, we are looking at the role of digital watermarking, as an important enabler for trading personal data in a safe, but also accountable manner. Digital watermarking is only one pillar of our efforts towards establishing data exchange systems that are accountable and private by design. More details on this soon!
Funded projects
- ProperData: NSF’s Secure and Trustworthy Cyberspace (SaTC) program.
- MLEDGE: Cloud and Edge Machine Learning (MLEDGE).
- DataBri-X: Data Process & Technological Bricks for expanding digital value creation in European Data Spaces.
Previous Projects:
- PIMCITY: Building The Next Generation Personal Data Platform — H2020 Innovation Action.
What´s new!
- [Aug 2020] Our paper on detecting sensitive urls on the web will be presented in ACM IMC’20.
- [June 2020] IMDEA participates via our group in the recently awarded NSF SaTC project “ProperData”.
- [Jan 2020] IMDEA participates via our group in the H2020 project “PIMCity”.
Job Offers
Actualmente no hay ofertas de trabajo en esta sección.
Contact
- Group leader: Nikolaos Laoutaris
- Email: nikolaos.laoutaris@networks.imdea.org
- Contact phone: +34 91 4 816 995
- Fax: 3491481696
Office & Postal Address
- IMDEA Networks Institute
- Avda. del Mar Mediterraneo, 22
- 28918 Leganes (Madrid)
- SPAIN